Code
library(RESI)Registered S3 method overwritten by 'clubSandwich':
method from
bread.mlm sandwichCode
library(reactable)
reactable(insurance)Types of variables
Distribution/Density features
Bivariate distribution features
Below are some questions related to some of the material we’ve covered so far. We’ll look at an insurance dataset with the amount of charges as a function of health and demographic features.
Insurance companies are often interested in predicting charges so that they can know who high-risk individuals are based on easily measurable demographic information.
library(RESI)Registered S3 method overwritten by 'clubSandwich':
method from
bread.mlm sandwichlibrary(reactable)
reactable(insurance)The table below summarizes the variables in the dataset for nonsmokers smokers. For each of the variables in the table below, comment on the skewness and whether the variables look similar or different between smokers and nonsmokers.
insurance$smoker = factor(insurance$smoker, labels = c('Nonsmoker', 'Smoker'))
label(insurance$smoker) = 'Smoking Status'
table1(~ age + bmi + children + sex + region + charges | smoker, data=insurance)| Nonsmoker (N=1064) |
Smoker (N=274) |
Overall (N=1338) |
|
|---|---|---|---|
| age | |||
| Mean (SD) | 39.4 (14.1) | 38.5 (13.9) | 39.2 (14.0) |
| Median [Min, Max] | 40.0 [18.0, 64.0] | 38.0 [18.0, 64.0] | 39.0 [18.0, 64.0] |
| bmi | |||
| Mean (SD) | 30.7 (6.04) | 30.7 (6.32) | 30.7 (6.10) |
| Median [Min, Max] | 30.4 [16.0, 53.1] | 30.4 [17.2, 52.6] | 30.4 [16.0, 53.1] |
| children | |||
| Mean (SD) | 1.09 (1.22) | 1.11 (1.16) | 1.09 (1.21) |
| Median [Min, Max] | 1.00 [0, 5.00] | 1.00 [0, 5.00] | 1.00 [0, 5.00] |
| sex | |||
| female | 547 (51.4%) | 115 (42.0%) | 662 (49.5%) |
| male | 517 (48.6%) | 159 (58.0%) | 676 (50.5%) |
| region | |||
| northeast | 257 (24.2%) | 67 (24.5%) | 324 (24.2%) |
| northwest | 267 (25.1%) | 58 (21.2%) | 325 (24.3%) |
| southeast | 273 (25.7%) | 91 (33.2%) | 364 (27.2%) |
| southwest | 267 (25.1%) | 58 (21.2%) | 325 (24.3%) |
| charges | |||
| Mean (SD) | 8430 (5990) | 32100 (11500) | 13300 (12100) |
| Median [Min, Max] | 7350 [1120, 36900] | 34500 [12800, 63800] | 9380 [1120, 63800] |
The plots below summarize each of the variables separately using histograms with densities.
par(mfrow=c(2,2))
invisible(sapply(names(insurance)[sapply(insurance, is.numeric)], function(name){ hist(insurance[,name], xlab=name, main=name, freq=FALSE); lines(density(insurance[,name], adjust=1.5), lwd = 2) } ))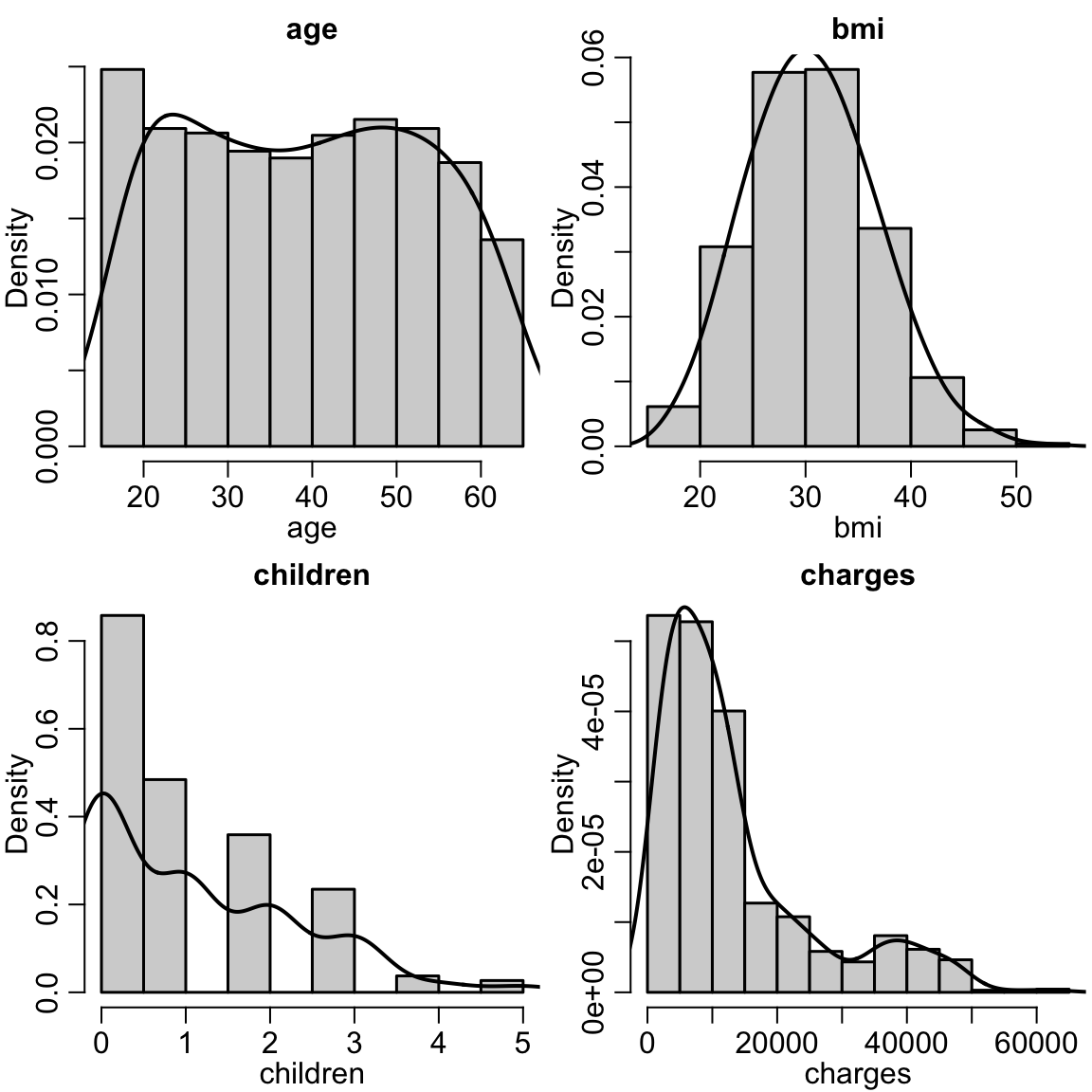
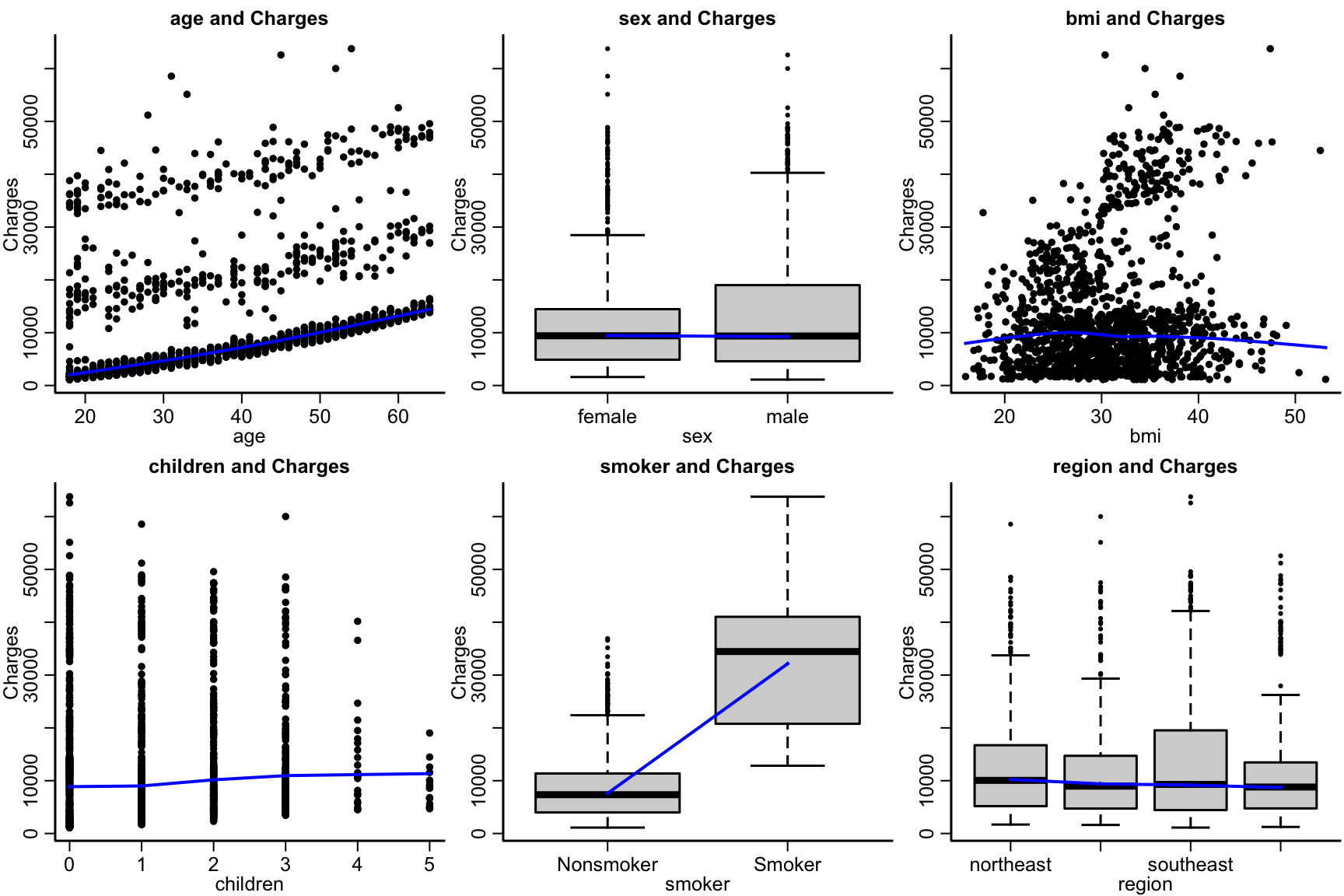
For each of the plots comment on the correlation and dependence of the variables with the number of charges.
par(mfrow=c(2,3))
xvars = names(insurance)[1:6]
insurance$sex = factor(insurance$sex)
insurance$region = factor(insurance$region)
invisible(sapply(xvars, function(xvar){
if(!is.factor(xvar)){
plot(insurance[,xvar], insurance$charges, ylab='Charges', xlab=xvar, main=paste(xvar, 'and', 'Charges') )
# remove missing values for lowess fit
subset = na.omit(insurance[, c(xvar, 'charges')])
lines(lowess( subset[,xvar], subset$charges), col='blue', lwd=2)
} else {
barplot(as.formula(paste('charges ~', xvar)), data=insurance)
}
}))
Dependence/Independence Discrete random variables Continuous random variables Expected values/Averages CDF, PDF
| Bernoulli values x | probabilities |
|---|---|
| 0 (nonsmoker) | 1-p |
| 1 (smoker) | p |
Some questions:
insurance dataset is a random sample from X_i \sim \text{Be}(p), for i=1, \ldots, 1338.| y=Number of children | \mathbb{P}(Y=y) |
|---|---|
| 0 | ___ |
| 1 | ___ |
| 2 | ___ |
| 3 | ___ |
| 4 | ___ |
| 5 | ___ |
| 6+ | ___?? |
region and estimate the probabilities from the dataset.
From the insurance dataset
BMI is a continuous random variable, \mathrm{BMI} = \mathrm{weight}/\mathrm{height}^2
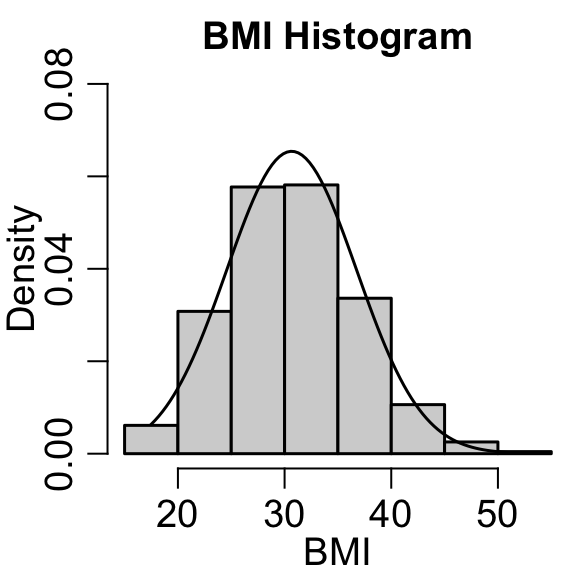
Here’s a plot from the insurance dataset.
It looks approximately normally distributed (not quite).
I’ve drawn the normal density on top
library(RESI)
lims = hist(insurance$bmi, freq = FALSE, ylim=c(0, .08), main='BMI Histogram', xlab='BMI')
x = seq(min(lims$mids), max(lims$mids), length.out=100)
lines(x, dnorm(x, mean = mean(insurance$bmi),sd=sd(insurance$bmi)))