Code
library(RESI)Registered S3 method overwritten by 'clubSandwich':
method from
bread.mlm sandwichCode
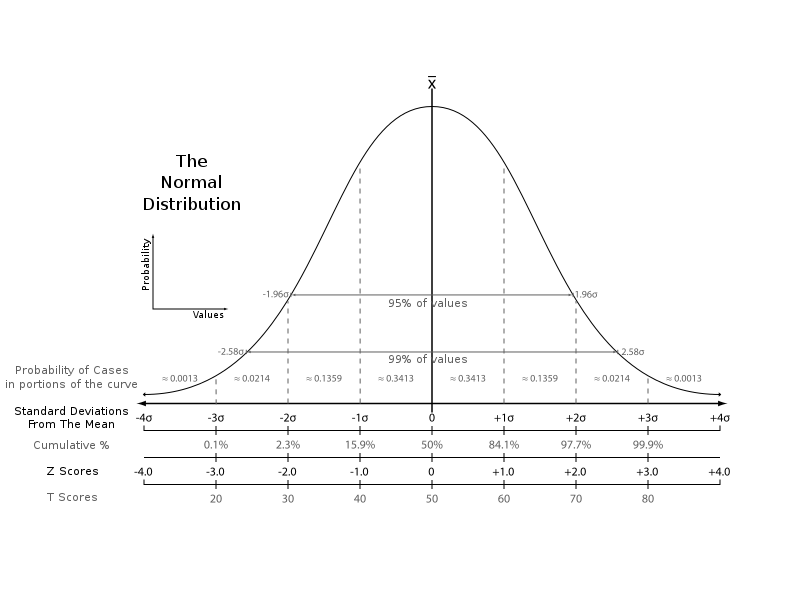
lims = hist(insurance$bmi, freq = FALSE, ylim=c(0, .08), main='BMI Histogram', xlab='BMI')
x = seq(min(lims$mids), max(lims$mids), length.out=100)
lines(x, dnorm(x, mean = mean(insurance$bmi),sd=sd(insurance$bmi)))