Learn to construct a confidence interval and test statistic
Review of mean and expectation
Let’s find the mean and variance of a Bernoulli random variable.
Jointly distributed random variables
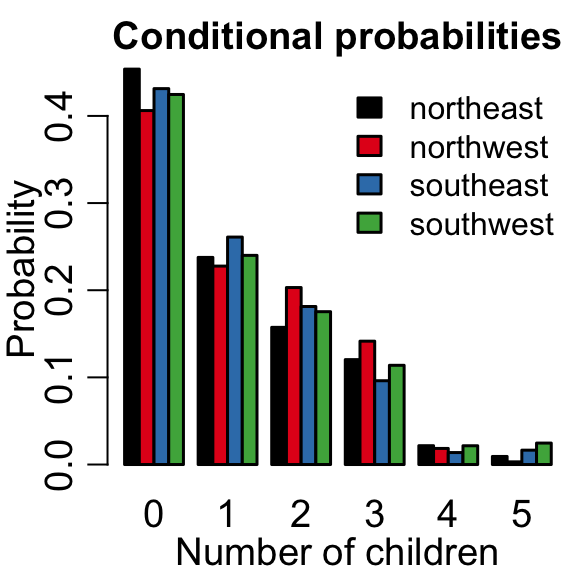
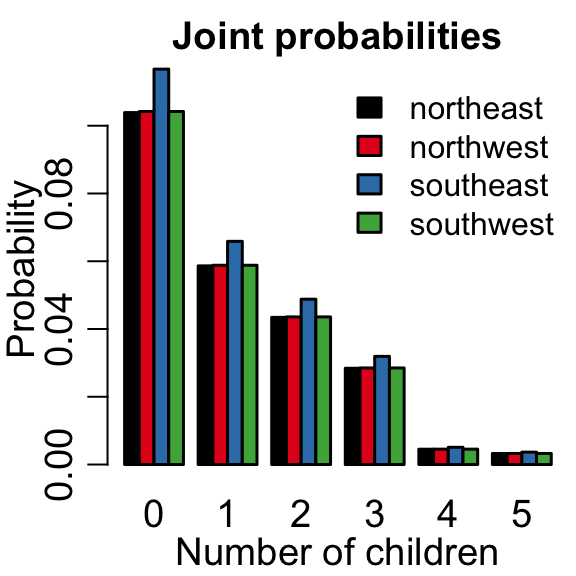
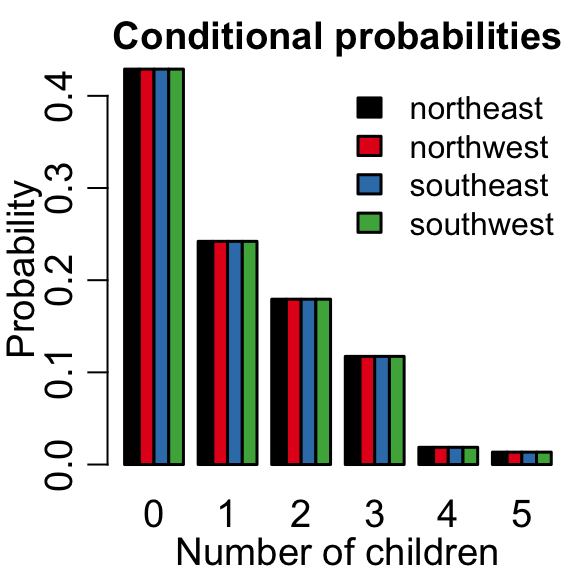
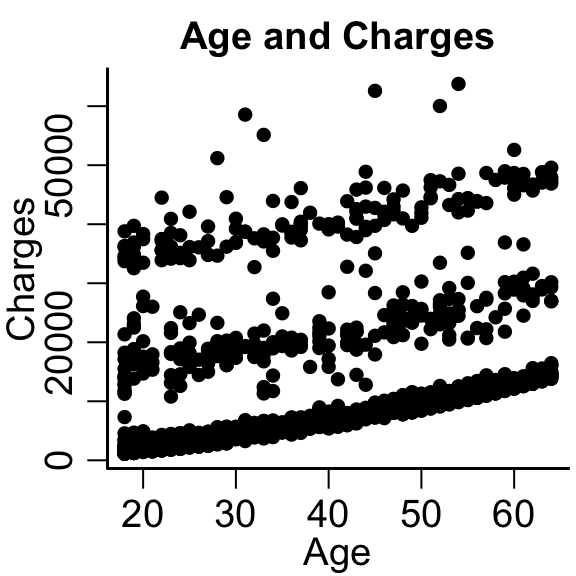
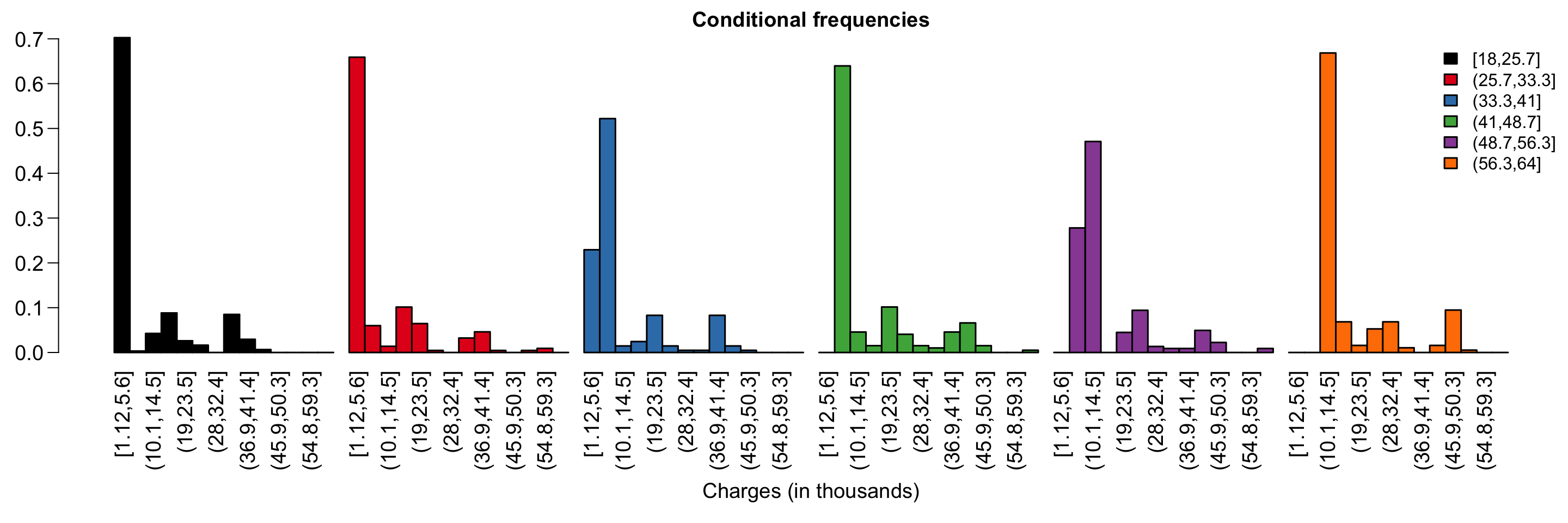
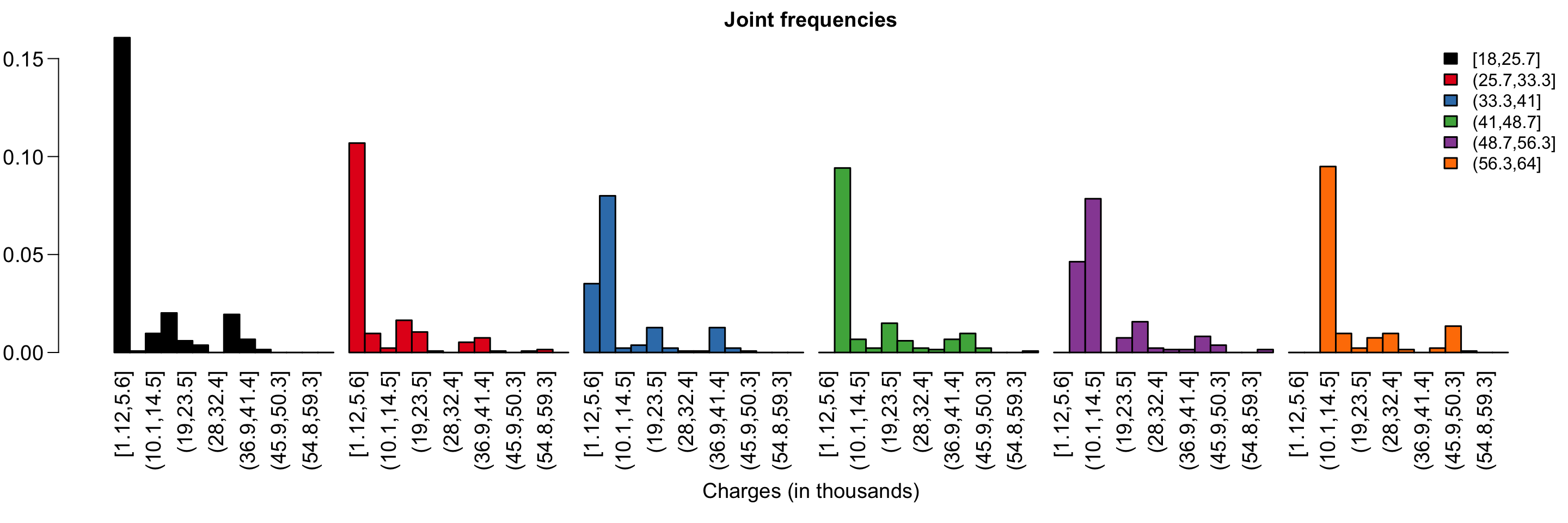
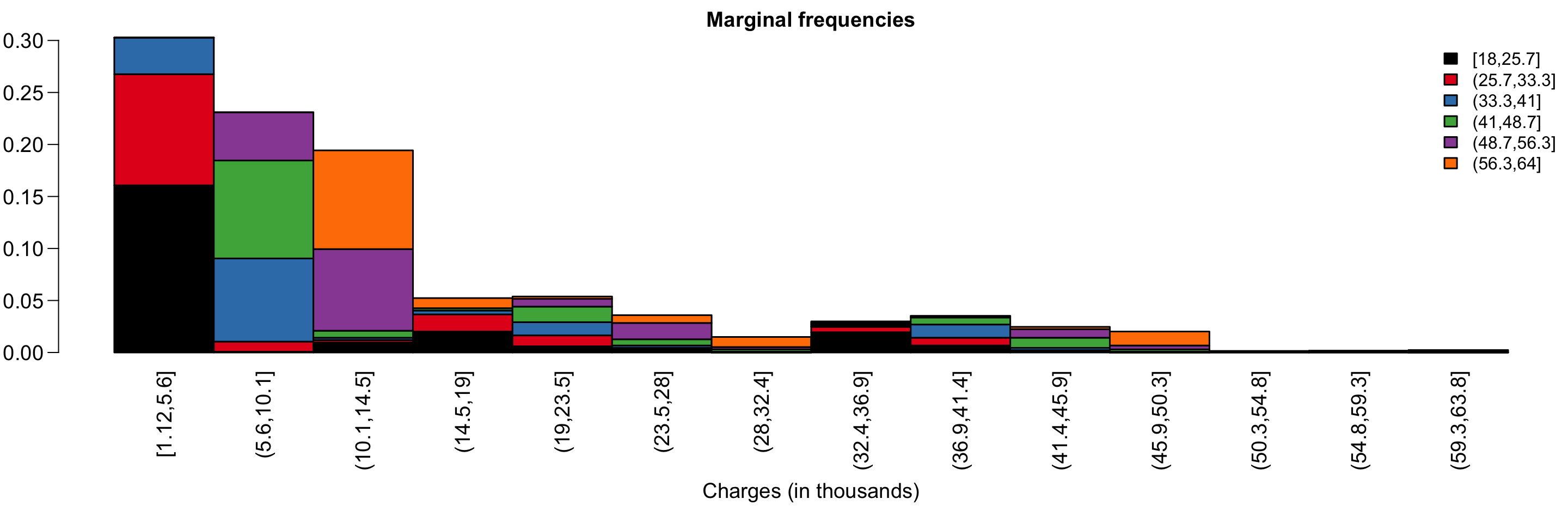
Jointly distributed random variables describe the probability of two things occurring. In the insurance dataset, we can consider the probability of having a certain number of children living in a certain area.
Code
library(RESI) # contains insurance dataset
Registered S3 method overwritten by 'clubSandwich':
method from
bread.mlm sandwich
Connecting data and probability with a random sample
Statistics is a way to learn about the world from a data set
For now, let’s work with the question, “What is the proportion of people in the United States who smoke cigarettes?”
We’ll define currently smoking cigarettes as anyone who has smoked at least one in the last 30 days.
One way to answer this question is to ask everyone in the US whether the smoke.
Another way is to ask a random sample of people whether they smoke.
How do we know that the proportion from the random sample is close to the proportion in the population?
Probability is the tool we use to tie information from our sample to the population we want to learn about.
In this example, we can assume people from the US are sampled randomly and that each person’s answer is X_i \sim \text{Be}(p)
If we repeated this for n independently sample people, X_1, \ldots, X_n is called a random sample.
There are three objects here:
p - the unknown parameter
X_1, \ldots, X_n - the random sample, which can be use to compute an estimator.
x_1, \ldots, x_n - the observed data, which can be used to compute and estimate.
Let’s see what this looks like in a simulation. A simulation lets us create a very simple fake world, where we know parameters, which we are usually not able to know.
Code
nsduh =readRDS('nsduh/puf.rds')# Pretend that the NSDUH dataset is the entire population of# the united states -- There are n=56,897 people in the US.table(nsduh$cigmon)
no yes
46209 10688
Code
# This is the parameter that we usually don't get to see.# We can only see it here, because we are pretending that# the NSDUH data is the full population of the US.p =mean(nsduh$cigmon=='yes')p
[1] 0.1878482
Code
# The sample size we choose.n =50# Capital X represents a random sample from the population.# This is just a statistical concept that tells us what would# happen if we repeated the experiment a whole bunch of times.## run X() at the command line multiple times to see that it# it changes each timeX =function(n=50) sample(nsduh$cigmon, n, replace =TRUE)X(n)
[1] no no yes no no no no no no no yes no no no no no no yes no
[20] yes no yes yes no no no no yes no yes no no no no no no no no
[39] no no no no no no no no no no yes no
Levels: no yes
Code
X(n)
[1] no no yes no no no yes no no no no no no no no no no no no
[20] no no no no yes no no no no no yes no no no no no no no no
[39] no yes no no no no yes no yes no no no
Levels: no yes
Code
X(n)
[1] no no no no no no no no yes no no no no no no no no yes no
[20] no no yes no no yes no no no no no no yes no no no no no no
[39] no no no no yes no no no no yes no no
Levels: no yes
Code
# x is our observed data, it is not random, but we assume it was# drawn as a random sample from the populationx =X(n)x
[1] no no yes no yes yes no no no yes no no no no yes no no yes no
[20] no no no no no yes no no no no no no no no no no yes no yes
[39] no no no no no no no no no yes no no
Levels: no yes
Code
# it does not change each timex
[1] no no yes no yes yes no no no yes no no no no yes no no yes no
[20] no no no no no yes no no no no no no no no no no yes no yes
[39] no no no no no no no no no yes no no
Levels: no yes
Code
x
[1] no no yes no yes yes no no no yes no no no no yes no no yes no
[20] no no no no no yes no no no no no no no no no no yes no yes
[39] no no no no no no no no no yes no no
Levels: no yes
Statistics tries to learn about the parameter p, using only the data x, by studying the mathematical properties of X.
X can tell us features about what would happen if we ran an experiment a whole bunch of times.
Mathematically
Parameters
Usually a parameter is defined based on the interest of the clinician and from the model for your data.
In this case, we assumed that each participant has a random probability of smoking with probability p.
Estimates
Note, an estimate is a function of the observed sample and it is nonrandom (Why is it non random?). We often use lowercase letters to make that clear
\bar x = n^{-1} \sum_{i=1}^n x_i.
Estimators
An estimator is a function of a random sample. The goal (usually) is to estimate a parameter of interest (here, p). Let’s consider the estimator
\hat p = \bar X = n^{-1} \sum_{i=1}^n X_i,
which we determine is pretty reasonable since \mathbb{E} \bar X = p.
We can study the properties of estimators to learn about how they behave.
If we like an estimator we can compute an estimate using our sample.
We can use features of our estimator to make probabilistic statements about what might happen if we repeat our study. Dataset-to-dataset variability
We can start to think about properties of the estimator to understand what it looks like if I were to repeat a study a whole bunch of times
What is the mean of the estimator?
What is the variance of the estimator?
Why do we care about this? Because we want to know the probability that our estimator is close to the value in the population.
Code
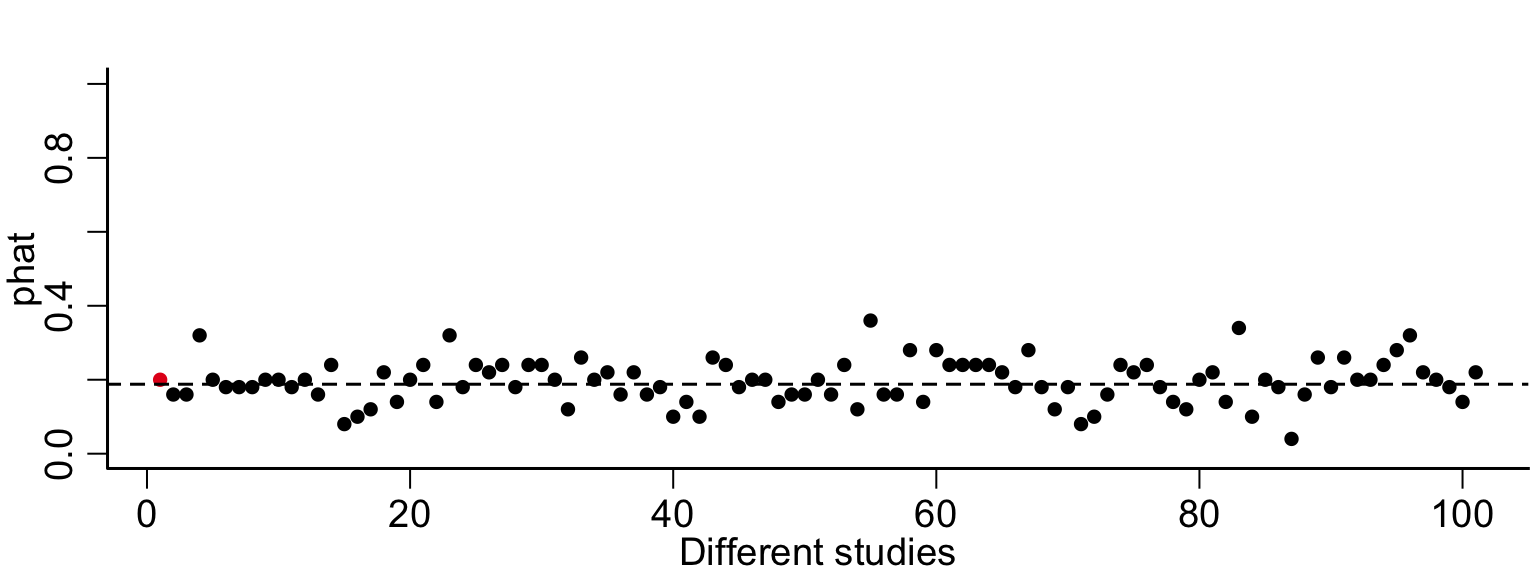
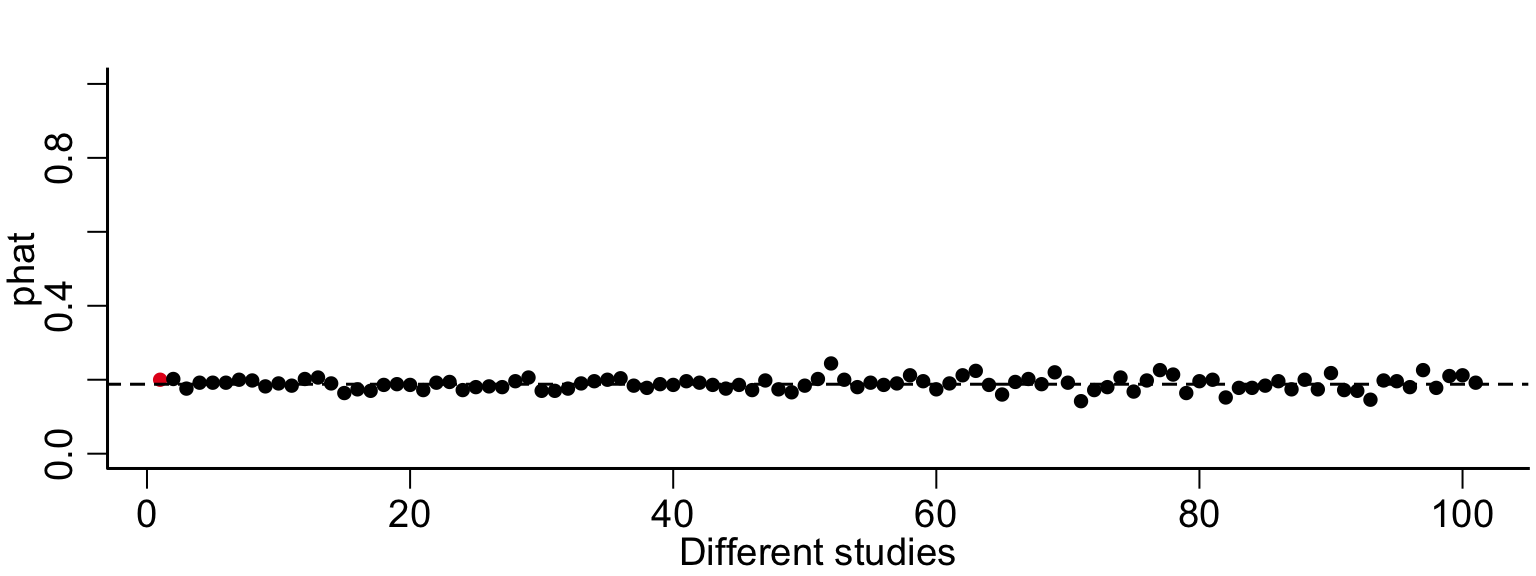
n=50# p is the unknown parameter.p =mean(nsduh$cigmon=='yes')# this is the data we collected, it was a random sample from the populationx =X(n)# this is the proportion of smokers we observedphatObs =mean(x=='yes')# this is an estimate the variance of the estimator phatVar_phat = phatObs * (1-phatObs)/n# How can we tell where p is if we don't get to see it?# We can't know for sure, but we can see how often the random variable version of phat is close to pnstudies =100phats =rep(NA, nstudies)for(i in1:nstudies){ phats[i] =mean(X(n)=='yes')}plot(c(phatObs, phats), xlab='Different studies', ylab='phat', ylim=c(0,1), col=c(cols[2], rep(cols[1], nstudies)) )abline(h=p, lty=2)
Code
# because phatObs was created the same way as the phat
Code
n=500# p is the unknown parameter.p =mean(nsduh$cigmon=='yes')# this is the data we collected, it was a random sample from the populationx =X(n)# this is the proportion of smokers we observedphatObs =mean(x=='yes')# this is an estimate the variance of the estimator phatVar_phat = phatObs * (1-phatObs)/n# How can we tell where p is if we don't get to see it?# We can't know for sure, but we can see how often the random variable version of phat is close to pnstudies =100phats =rep(NA, nstudies)for(i in1:nstudies){ phats[i] =mean(X(n)=='yes')}plot(c(phatObs, phats), xlab='Different studies', ylab='phat', ylim=c(0,1), col=c(cols[2], rep(cols[1], nstudies)) )abline(h=p, lty=2)
Code
# because phatObs was created the same way as the phat
Some common statistical jargon so far
Types of variables
Categorical variable - a variable that takes discrete values, such as diagnosis, sex,
Continuous variable - a variable that can take any values within a range, such as age, blood pressure, brain volume.
Ordinal variable - a categorical variable that can be ordered, such as age category, Likert scales, Number of days, Number of occurrences.
Discrete random variable - takes integer values.
Continuous random variable - takes real values.
Distribution/Density features
Mode/ Non-modal/Unimodal/ Bimodal - a peak in a density.
Non-modal - no peak
Unimodal - one peak
Bimodal - two peaks
Quantile - the pth quantile, q_p divides the distribution such that p% of the data are below q_p.
Median - 50th quantile of a distribution
Skew/Skewness - the amount of asymmetry of a distribution
Symmetric distribution - a distribution with no skew
Kurtosis - the heavy tailed-ness of a distribution.
Probability Density/Mass Function - function, f_X, that represents f_X(x) = \mathbb{P}(X=x)
Cumulative Distribution Function - function, F_X that represents F_X(x) = \mathbb{P}(X\le x)
Parameter – Target unknown feature of a population (nonrandom)
Estimate – Value computed from observed data to approximate the parameter (nonrandom)
Estimator – A function of a random sample to approximate the parameter